TL;DR: Text AutoEncoder pre-trained on unsupervised denoising task to generalize on downstream text classification. Paper provides a lot of context by comparing many text embedding methods on heterogeneous domains.
Idea
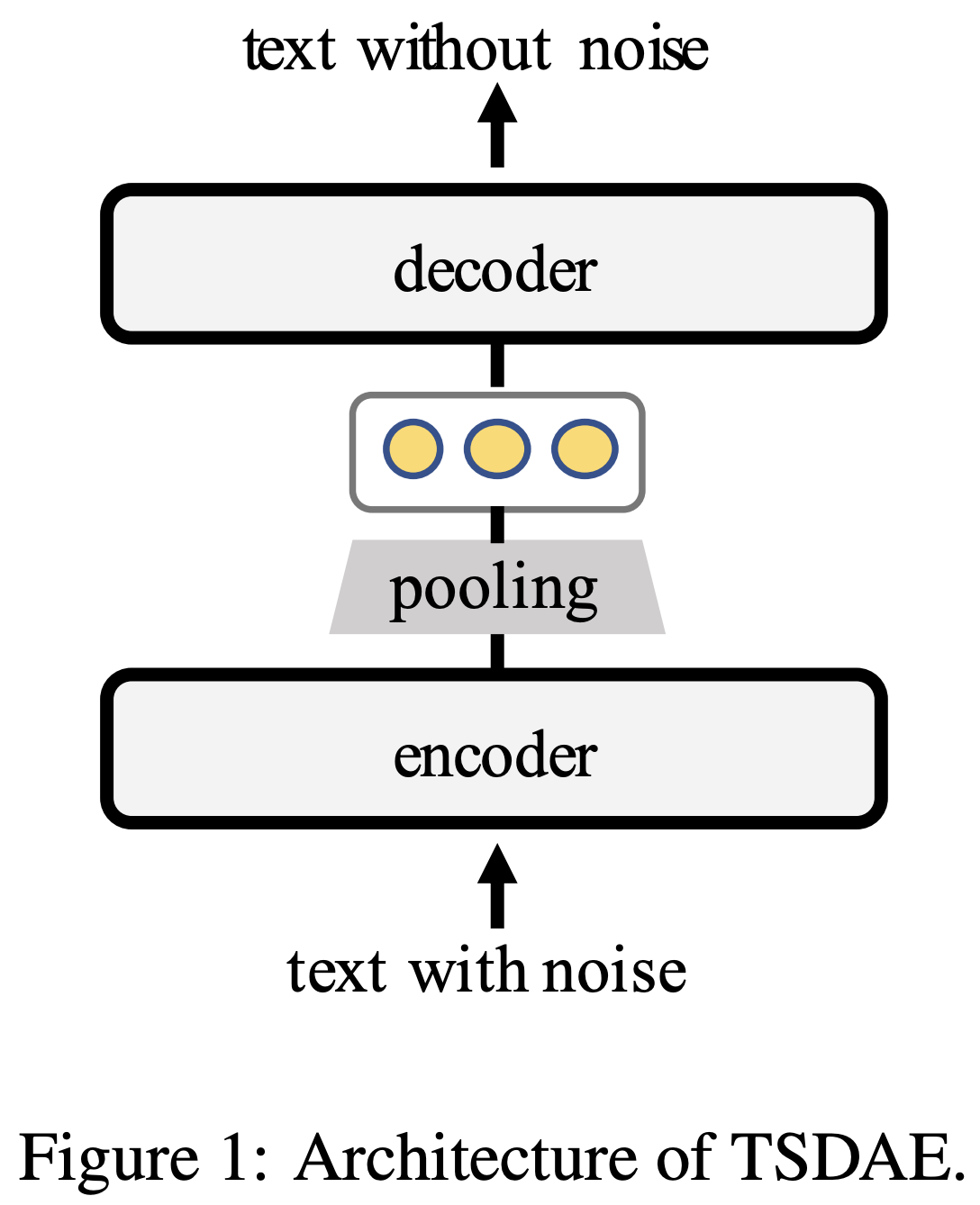
Authors aim to train a model in unsupervised or semi-supervised manner to extract meaningful text embeddings. In order to do it, they build an encoder-decoder architecture similar to Transformer to reconstruct an input text. However, unlike Transformer, the decoder has as access only to a single text embedding extracted by the encoder in the form of the output of the [CLS] token. Additionally, authors corrupt an input text by deleting 60% of tokens.
Experimental setup
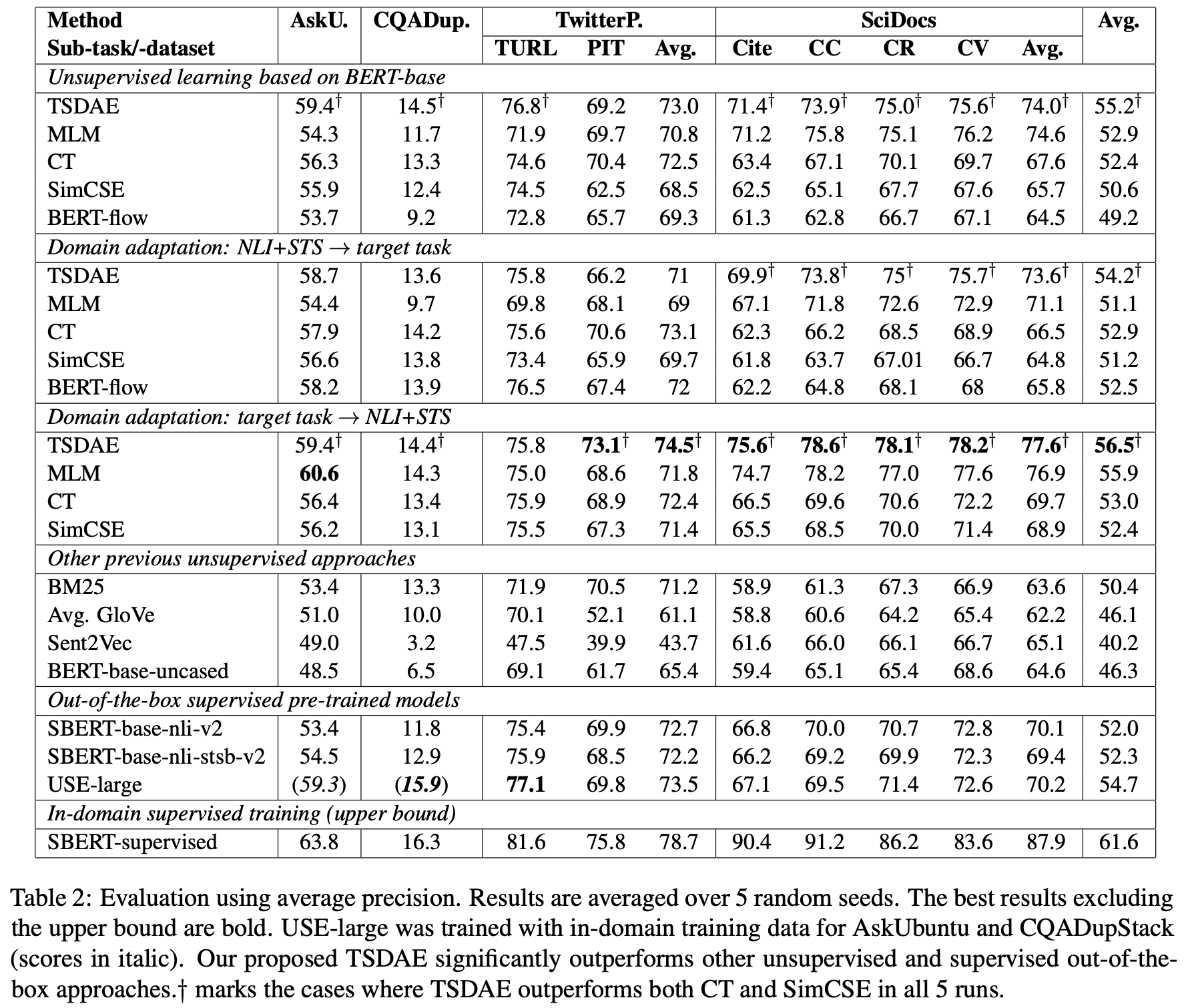
Arguing that the previously reported performance on STS () dataset poorly correlate with the performance real-world tasks, authors compare TSDAE to other methods on AskUbuntu (Re-Ranking), CQADupStack (Information Retrieval), TwitterPara (Paraphrase Identification), and SciDocs (Re-Ranking) datasets. In all tasks, the model is required to measure the similarity between an input query and a set of candidates. The paper utilize cosine similarity between text embeddings.
Training setup
The TSDAE approach is tested in three settings: unsupervised learning, domain Adaptation and pre-training.
- Unsupervised Learning: model have access only to unlabeled sentences from the target task.
- Domain adaptation: model have access to unlabeled sentences from the target task and labeled sentences from NLI and STS benchmark. Two setups were tested: 1) training on NLI+STS data, then unsupervised training to the target domain, 2) unsupervised training on the target domain, then supervised training on NLI + STS.
- Pre-Training: model have access to a larger collection of unlabeled sentences from the target task and a smaller set of labeled sentences from the target task.
Baselines
TSDAE is compared to various approaches.
Pre-trained Transformer-based unsupervised methods:
- MLM (Masked-Language-Model): mean pooling over the BERT output token embeddings.
- CT (Contrastive Tension) finetunes pre-trained Transformers in a contrastive-learning fashion. Views the identical sentences as the positive examples. Uses two models with the same initial parameters to encode first and second texts respectively.
- SimCSE: same as CT, but applies different dropout masks for the same sentence and uses single model.
- BERT-flow freezes BERT weights and pushes token embeddings close to a standard Gaussian distribution. The text embeddings is obtained by pooling over processed token embeddings.
Other unsupervised approaches:
- BM25: term-matching method without trainable parameters.
- GloVe: mean pooling over the GloVe embeddings trained on a large corpus from the general domain.
- Sent2Vec: similar to GloVe model trained on the in-domain unlabeled corpus.
- BERT-base-uncased with mean pooling.
Results
The comparison results are presenter in the table below. Interestingly, a simple MLM approach scores higher than other specialized methods in most setups. Also, in domain adaptation setting, first training on the target domain, and then training with labeled NLI+STS achieves better results than the opposite direction. Overall, TSDAE shows the best results over all datasets.